
From Python to Julia: Feature Engineering and ML

This is part 2 in my two part series on getting started with Julia for applied data science. In the first article, we went through a few examples of simple data manipulation and conducting exploratory data analysis with Julia. In this blog, we will carry on the task of building a fraud detection model to identify fraudulent transactions.
To recap briefly, we used a credit card fraud detection dataset obtained from Kaggle. The dataset contains 30 features including transaction time, amount, and 28 principal component features obtained with PCA. Below is a screenshot of the first 5 instances of the dataset, loaded as a dataframe in Julia. Note that the transaction time feature records the elapsed time (in second) between the current transaction and the first transaction in the dataset.
Feature Engineering
Before training the fraud detection model, let’s prepare the data ready for the model to consume. Since the main purpose of this blog is to introduce Julia, we are not going to perform any feature selection or feature synthesis here.
Data splitting
When training a classification model, the data is typically split for training and test in a stratified manner. The main purpose is to maintain the distribution of the data with respect to the target class variable in both the training and test data. This is especially necessary when we are working with a dataset with extreme imbalance. The MLDataUtils package in Julia provides a series of preprocessing functions including data splitting, label encoding, and feature normalisation. The following code shows how to perform stratified sampling using the stratifiedobs function from MLDataUtils. A random seed can be set so that the same data split can be reproduced.
using MLDataUtils
using Random
# Convert dataframe to arrays
X = Array(df[!, Not(r"Class")])
X = transpose(X)
y = Array{Int64}(select(df, :Class))
y = vec(y)
Random.seed!(42);
(X_train, y_train), (X_test, y_test) = stratifiedobs((X, y), p = 0.7)
X_train = transpose(X_train)
X_test = transpose(X_test)
println(size(X_train))
println(size(X_test))
println(size(y_train))
println(size(y_test))The usage of the stratifiedobs function is quite similar to the train_test_split function from the sklearn library in Python. Take note that the input features X need to go through twice of transpose to restore the original dimensions of the dataset. This can be confusing for a Julia novice like me. I’m not sure why the author of MLDataUtils developed the function in this way.
The equivalent Python sklearn implementation is as follows.
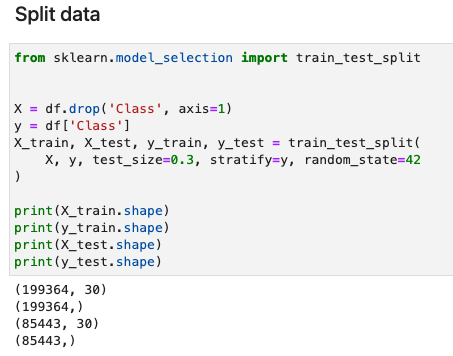
Split data for training and test - Python implementation
Feature scaling
As a recommended practice in machine learning, feature scaling brings the features to the same or similar ranges of values or distribution. Feature scaling helps improve the speed of convergence when training neural networks, and also avoids the domination of any individual feature during training.
Although we are not training a neural network model in this work, I’d still like to find out how feature scaling can be performed in Julia. Unfortunately, I could not find a Julia library which provides both functions of fitting scaler and transforming features. The feature normalization functions provided in the MLDataUtils package allow users to derive the mean and standard deviation of the features, but they cannot be easily applied on the training / test datasets to transform the features. Since the mean and standard deviation of the features can be easily calculated in Julia, we can implement the process of standard scaling manually.
The following code creates a copy of X_train and X_test, and calculates the mean and standard deviation of each feature in a loop.
num_features = size(X_train)[2]
X_train_scaled = copy(X_train)
X_test_scaled = copy(X_test)
for col in 1:num_features
feature_mean = mean(X_train[:, col])
feature_std = std(X_train[:, col])
X_train_scaled[:, col] = [i-feature_mean for i in X_train[:, col]] / feature_std
X_test_scaled[:, col] = [j-feature_mean for j in X_test[:, col]] / feature_std
end
println(size(X_train_scaled))
println(size(X_test_scaled))The transformed and original features are shown as follows.
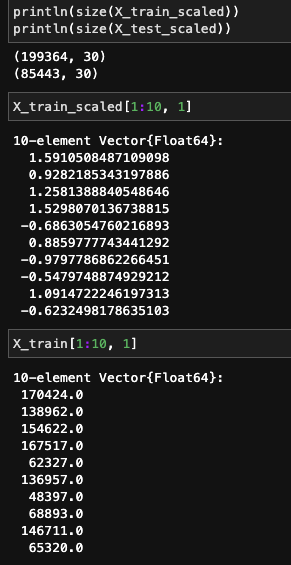
Scaled features vs. orginal features - Julia implementation
In Python, sklearn provides various options for feature scaling, including normalization and standardization. By declaring a feature scaler, the scaling can be done with two lines of code. The following code gives an example of using a RobustScaler.
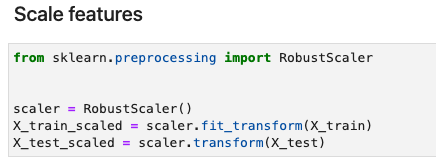
Perform robust scaling to the features - Python implementation
Oversampling (by PyCall)
A fraud detection dataset is typically severely imbalanced. For instance, the ratio of negative over positive examples of our dataset is above 500:1. Since obtaining more data points is not possible, undersampling will result in a huge loss of data points from the majority class, oversampling becomes the best option in this case. Here I apply the popular SMOTE method to create synthetic examples for the positive class.
Currently, there is no working Julia library which provides implementation of SMOTE. The ClassImbalance package has not been maintained for two years, and cannot be used with the recent versions of Julia. Fortunately, Julia allows us to call the ready-to-use Python packages using a wrapper library called PyCall.
To import a Python library to Julia, we need to install PyCall and specify the PYTHONPATH as an environment variable. I tried create a Python virtual environment here but it did not work out. Due to some reason, Julia cannot recognize the python path of the virtual environment. This is why I have to specify the system default python path. After this, we can import the Python implementation of SMOTE, which is provided in the imbalanced-learn library. The pyimport function provided by PyCall can be used to import the Python libraries in Julia. The following code shows how to activate PyCall and ask for help from Python in a Julia kernel.
ENV["PYTHON"] = "/usr/bin/python3"
using PyCall
imbo = pyimport("imblearn.over_sampling")
sm = imbo.SMOTE(random_state=42)
X_train_sm, y_train_sm = sm.fit_resample(X_train_scaled, y_train)
size(X_train_sm), size(y_train_sm)The equivalent Python implementation is as follows. We can see the fit_resample function is used in the same way in Julia.
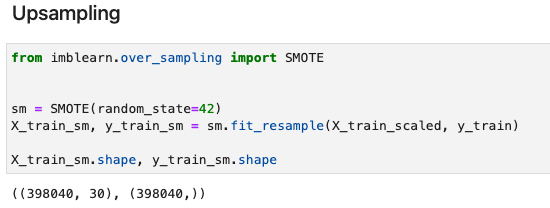
Upsampling training data with SMOTE - Python implementation
Model Training
Now we reach the stage of model training. We will be training a binary classifier, which can be done with a variety of ML algorithms, including logistic regression, decision tree, and neural networks. Currently, the resources for ML in Julia are distributed across multiple Julia libraries. Let me list down a few most popular options with their specialized set of models.
- MLJ: traditional ML algorithms
- ScikitLearn: traditional ML algorithms
- Mocha: neural networks
- Flux: neural networks
Here I’m going to choose XGBoost, considering its simplicity and superior performance over the traditional regression and classification problems. The process of training a XGBoost model in Julia is the same as that of Python, albeit there’s some minor difference in syntax.
using XGBoost
dtrain = DMatrix(X_train_sm, label = y_train_sm)
y_test_vec = Vector(y_test)
dtest = DMatrix(X_test_scaled, label = y_test_vec)
param = [
"eta" => 0.1,
"objective" => "binary:logistic"
]
t = @time model = xgboost(dtrain, 1000, param=param, eval_set=dtest)
tThe equivalent Python implementation is as follows.

Train a fraud detection model with XGBoost - Python implementation
Model Evaluation
Finally, let’s look at how our model performs by looking at the precision, recall obtained on the test data, as well as the time spent on training the model. In Julia, the precision, recall metrics can be calculated using the EvalMetrics library. An alternative package is MLJBase for the same purpose.
using EvalMetrics
y_pred_prob = XGBoost.predict(model, X_test_scaled)
# Calculate precision, recall scores
precision(y_test_vec, y_pred_prob, 0.5), recall(y_test_vec, y_pred_prob, 0.5)In Python, we can employ sklearn to calculate the metrics.
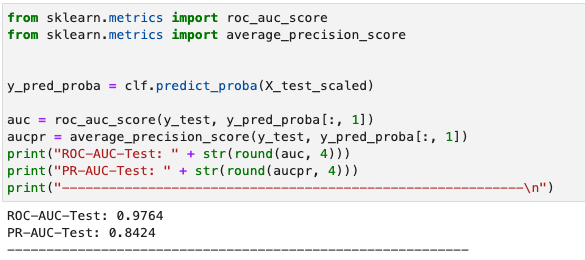
Calculate precision, recall - Python implementation
So which is the winner between Julia and Python? To make a fair comparison, the two models were both trained with the default hyperparameters, and learning rate = 0.1, no. of estimators = 1000. The performance metrics are summarized in the following table.
| Language | Precision | Recall | Training time (in second) |
|---|---|---|---|
| Julia | 0.8531 | 0.8243 | 419.2983 |
| Python | 0.8322 | 0.8041 | 408.4061 |
It can be observed that the Julia model achieves a better precision and recall with a slightly longer training time. Since the XGBoost library used for training the Python model is written in C++ under the hood, whereas the Julia XGBoost library is completely written in Julia, Julia does run as fast as C++, just as it claimed!
The hardware used for the aforementioned test: 11th Gen Intel® Core™ i7-1165G7 @ 2.80GHz - 4 cores.
Jupyter notebook can be found on Github.
Takeways
I’d like to end this series with a summary of the mentioned Julia libraries for different data science tasks.
| Task | Julia library | Equivalent Python library |
|---|---|---|
| Data manipulation | DataFrames | pandas |
| Plotting statistical graphs | StatsPlots, Plots | matplotlib, seaborn, plotly |
| Feature engineering | MLDataUtils | scikit-learn |
| Model training | MLJ, ScikitLearn, Mocha, Flux | scikit-learn, TensorFlow, PyTorch |
| Model evaluation | EvalMetrics, MLJBase | scikit-learn |
Due to the lack of community support, the usability of Julia cannot be compared to Python at the moment. Nonetheless, given its superior performance, Julia still has a great potential in future.
References
- Credit Card Fraud Detection dataset: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
- Start Machine Learning With Julia: Top Julia Libraries for Machine Learning: https://www.analyticsvidhya.com/blog/2021/05/top-julia-machine-learning-libraries/